auch dieses Jahr unserer Tradition folgend wieder begeistert im Februar. Diesmal begaben wir uns auf eine kulinarische Reise nach Thailand und legten selber Hand an. Unter Anleitung von Profiköchen schwangen wir die Kochmesser im Wrenkh-Kochsalon in der Schanze und kochten uns quer durch die Bangkok Street Kitchen.
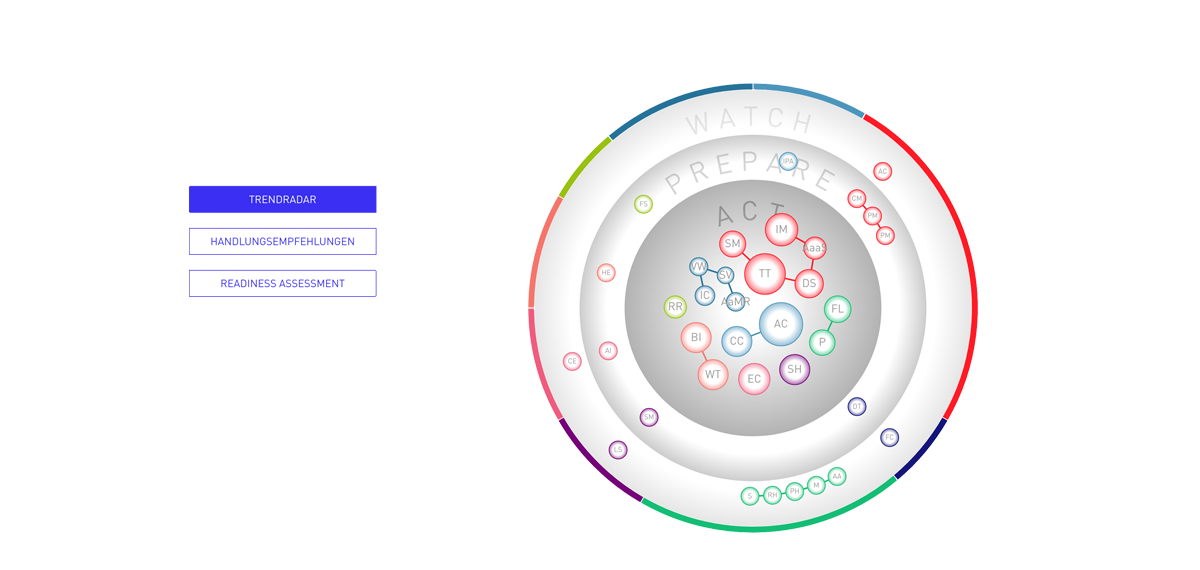
Trendradar
TRENDONE is a renowned Hamburg consulting firm for strategic future issues & trends.
In times when disruptive ideas, innovative developments and radical technical progress challenge many industries, enterprises structure themselves increasingly new. Innovation processes are being embedded into organizations and are the foundation for continuous adaptation of future development. TRENDONE provides substantial information about current trends for many different business environments. In addition, the Hamburg-based company has created a platform with the necessary tools for researching, evaluating and recording future developments and provides insights how a company is prepared for relevant trends.
One of these tools is the Trendmanager with the integrated Trendradar. The Trendmanager assists companies to detect relevant developments from all mega, macro and micro trends identified by TRENDONE. It allows them to store all findings in a company-specific trend pool and evaluates their future impact on the company. For these tasks, the Trendradar offers various views that categorize trends and correlates them. The view “Recommendations for Action” is subdivided into the three fields “Act”, “Prepare” and “Watch” and provides an overview of how relevant trends should be taken into account for innovation processes and corporate decisions. “Readiness Gap“ delivers insights into weaknesses and excellences of a company and where the focus should be set to ensure a successful future development.
In close cooperation with TRENDONE Folge 3 developed the views of the Trendradar over a period of several months by subsequently creating the visual concept and finally ensuring the implementation of the dynamic and animated views.
Zwischen Himmel und Hölle: UX in Zeiten von KI
In dem Vortrag „Zwischen Himmel und Hölle: UX in Zeiten von KI“ beleuchten der Produkt-Entwickler Dr. Christian Graf (Senior Consultant | User Experience – Ipsos GmbH | XING) und Folge 3-Geschäftsführer Christoph Fröhlich die Auswirkungen, die der Einsatz von KI-Technologien auf die User Experience digitaler Produkte hat.
Der Vortrag findet am Montag, dem 4. Februar 2019 im Rahmen des UX Roundtable in Hamburg statt.
7TV mit neuem Support-Bereich
Für maxdome/7TV haben wir den Online-Support auf eine neue technische Basis gestellt und ein mandantenfähiges System mit WordPress als CMS und einem Angular-Frontend realisiert.
Als erster Mandant ist FAQ 7TV im Januar online gegangen.
KI-Prognose-Systeme für die Logistik
Die Anwendungsgebiete für Künstliche Intelligenz in der Logistik sind vielfältiger Natur und über die ganze Supply Chain verteilt. Insbesondere Prognose-Systeme zur Auslastungsplanung stellen einen vielversprechenden Ansatz dar.
Wer hätte das vor 20 Jahren gedacht? Die Logistik-Branche wurde im Zuge der Digitalisierung nicht bedeutungslos, sondern das Gegenteil trat ein. Der Online-Handel boomt, immer mehr Produkte wollen verschickt werden und die Branche jagt von einem Rekord zum nächsten.
Mit den Mengen steigen auch die Anforderungen. Die Supply Chains werden stetig komplexer und die Abläufe müssen effizienter und effektiver werden. Gleichzeitig entstehen immer umfassendere Datenmengen, die genutzt werden können, um Prozesse zu optimieren, Muster zu erkennen oder Vorhersagen zu treffen.
Neuronale Netze sind ein Game Changer
Wo kein Mensch mehr die Menge der Daten überblicken und Rückschlüsse daraus ziehen kann, helfen Methoden des Machine Learning und der Künstlichen Intelligenz (KI). Insbesondere mit neuronalen Netze lassen sich Prognose- und Klassifizierungs-Probleme effizient angehen.
Dabei beschreiten Neuronale Netze einen ganz eigenen, neuartigen Lösungs-Ansatz. Sie sind mit den übrigen Verfahren des Machine Learning nicht vergleichbar und sie eröffnen Wege, wo bisher kein Weiterkommen war.
Entsprechend euphorisch sind die Hoffnungen, die mit ihrem Einsatz verbunden sind. Beispielhalber soll hier die McKinsey-Studie zum Potential neuronaler Netze erwähnt werden.
KI in der Logistik
Die Anwendungsgebiete für KI in der Logistik sind vielfältiger Natur und über die ganze Supply Chain verteilt. Eine Studie der IDG vom September 2018 führt insbesondere die folgenden drei Bereiche auf, in denen die Unternehmen über den Einsatz von KI nachdenken
- Optimierung der internen Prozesse
- Verbesserung der Kundenbeziehung
- Verbesserung der Fertigungsprozesse
Zwar sind viele Unternehmen noch in der Analysephase und haben noch keine Projekte realisiert, aber insbesondere bei den großen Anbietern lassen sich schon konkrete Beispiele finden, wie KI und Machine Learning in der Logistik erfolgreich eingesetzt wird.
Im E-Commerce lassen sich Absatzprognosen erstellen, um nachgefragte Waren in ausreichender Stückzahl vorzuhalten, wie es z.B. Otto macht. Zalando optimiert im Auslieferungs-Lager die Pickwege, um Aufträge schneller versandfertig zu bekommen. Und wir bei Folge 3 optimieren die Auslastung von Packbereichen, in dem wir prognostizieren, wie lange es braucht, um eine Bestellung versandfertig zu machen.
Entscheidend ist eine gute Datenbasis
Allerdings eignet sich nicht jede Idee für eine Umsetzung mit Machine Learning und KI. Nicht weil die Idee schlecht ist. Sondern weil die Daten, die zur Realisierung notwendig sind, nicht vorliegen.
Jedes Projekt, das Technologien aus der Data sciene einsetzen möchte – seien es Neuronale Netze, Recommender, Prognose-Systeme oder ähnliches – benötigt eine umfassende, qualitative Datenbasis. Die Daten sollten möglichst wenig Ausreißer enthalten, genügend Datensätze aufweisen und sie müssen ausreichend viele Merkmale aufweisen, um die gestellte Aufgabe aus den Daten heraus lösen zu können.
Insbesondere bei Prognose-Aufgaben ist es sehr wichtig, möglichst alle Merkmale, die für die Vorhersage der Zielgröße relevant sind, auch in den Daten zur Verfügung zu haben.
Oft stellt sich im Projekt heraus, dass nicht all diese Daten zur Verfügung stehen und eventuell auch gar nicht quantifizierbar sind oder nur mit erheblichem Aufwand beschafft werden können. Aus diesen Gründe ist es von Vorteil, DataScience-Projekte immer mit einer ausführlichen Analyse der vorliegenden Daten zu beginnen. Andernfalls besteht die Gefahr, dass Ressourcen in ein Projekt gesteckt werden, das sich später als undurchführbar erweist und abgebrochen werden muss.
Wenn Sie Nachfragen zu diesen Themen haben oder Sie sich für die Einsatzmöglichkeiten von KI in der Logistik interessieren, melden Sie sich gerne unverbindlich unter data@folge3.de
Künstliche Intelligenz in der Praxis
Am Freitag, dem 7. Dezember 2018 stellt Folge 3-Geschäftsführer Christoph Fröhlich im Business Innovation Lab der HAW Hamburg vor, wie mit Hilfe von Neuronalen Netzen die effiziente Auslastung knapper Ressourcen geplant werden kann.
Die Veranstaltung findet im Rahmen der AG Logistikkette der Hamburger Dialog-Plattform Industrie 4.0 statt.
… mehr zu diesem Projekt: KI-Prognose-Systeme für die Logistik
Museen Dresden: Virtuelles Museum ist online
Mehr als 120.000 Kunstobjekte der Museen in Dresden sind ab sofort online zugängig. Funktionen wie Stöbern, zielgerichtete Suche, kuratierte Touren und vor allem integrierte Live-Volltextsuche bieten einer breiten Öffentlichkeit den Einstieg in Exponate, die als unentdeckter Schatz jahrelang in den Archiven schlummerten.
Folge 3 war in den vergangenen drei Jahren an der Entstehung des Virtuellen Museums maßgeblich beteiligt: u.a. mit Strategy, Prototyping, Application Design, UX/UI, CMS, Implementierung und QM.
Folge 3 beim WUD 2018
Der World Usability Day (WUD) fand als weltweiter Tag für UX-Professionals auch in diesem Jahr wieder in Hamburg statt. Unter dem Schwerpunktthema „Design for Good or Evil“ besuchten wir auf dem Campus der HAW Hamburg Vorträge und Workshops z.B. über manipulative Designtechniken, Martial-Art-Design und Dark UX und konnten spannende Eindrücke und Anregungen mitnehmen.
Frankfurter Buchmesse: Künstliche Intelligenz und Neuronale Netze für Verlage
Am Mittwoch, dem 10. Oktober und am Donnerstag, dem 11. Oktober 2018 stellen wir auf der Buchmesse Frankfurt unsere KI-basierten Ideen für Prognosen und Text-Matching für die Verlagswelt vor.
Sprechen Sie uns gerne an, wenn Sie ebenfalls auf der Buchmesse sind und sich dafür interessieren.
… mehr zu diesem Projekt: Neuronale Netze zur Prognose von Online-Reichweite
Consim: Ähnliche Texte finden
Consim ist ein Matching-System für Text. Mit Consim lassen sich Texte identifizieren, die ähnliche Themen behandeln. Consim erkennt die Ähnlichkeit von Texten mit Hilfe von Machine Learning und Natural Language Processing rein auf inhaltlicher Basis. Es werden keine Besucher-Daten oder weitere Meta-Informationen benötigt.
Beispielsweise kann Consim in den Angeboten eines Nachrichten-Verbundes Texte zu ähnlichen Themen finden. Sogar dann, wenn Sie auf verschiedenen Portalen gehostet werden. Oder Consim kann mit den Gesetzestexten eines Rechtsgebietes trainiert werden und findet dann Gerichtsurteile, in denen die jeweiligen Themen behandelt werden.
Ähnlichkeit basiert auf dem Inhalt
Um Consim einzusetzen reicht es, Zugriff auf die Inhalte zu haben. Metadaten wie Kategorisierung, Quelle oder ähnliches können als zusätzliche Hilfestellung mit in den Matching-Prozess einfliessen, sind aber nicht nötig.
Das System basiert auch nicht auf der Auswertung von User-Daten. Es ermittelt also nicht – anders als der klassische Amazon-Recommender – dass ein User, der Produkt A mochte, auch Produkt B angeschaut hat. Vielmehr identifiziert Consim Wortgruppen, die eine thematische Einordnung des Textcontents erlauben.
Dadurch, dass Consim nur den Inhalt in Betracht zieht, funktioniert das System auch direkt für neu eingestellte Texte – es gibt kein Cold-Start-Problem – und auch in Bereichen, in denen nur wenige oder gar keine User-Interaktionen statt finden.
Use-Cases
Consim kann beispielsweise für die folgenden Anwendungsfälle eingesetzt werden:
- Online-Nachrichtenportale: Mehr und mehr Nachrichtenportale setzten auf einen Mix aus freien News und Premium-Inhalten, die hinter einer Bezahl-Schranke liegen. Mit Hilfe von Consim lassen sich thematische Verbindungen finden, die von den freien, hoch frequentierten Online-Angeboten auf die weniger oft aufgerufenen Bezahl-Inhalte führen. Klassische Recommender-Lösungen scheitern hier, weil die Bezahl-Inhalte zu wenig Reichweite haben, um von den statistischen Verfahren berücksichtigt zu werden.
- In Matching – Szenarien, in denen individuelle, profil-basierte Vorschläge erstellt werden, läßt Consim sich ebenfalls einsetzen. Voraussetzung ist, dass die Informationen, die zur Identifikation von Interessen und zur Herausarbeitung eines Profils verwendet werden, in Textform vorliegen. Dazu können sowohl vom User generierte als auch von ihm konsumierte Inhalte verwendet werden. Ein Anwendungsfall ist das Matching von Studieninteressen mit Studiengangs-Beschreibungen. Ein anderer ist die Suche in Stellenangeboten, wo die bereits besuchten und als interessant bewerteten Angebote das Profil ergeben, zu dem sich ähnliche Angebote finden lassen.
- In Expertensystemen oder Fallsammlungen für Spezialisten lassen sich mit Consim ähnliche Fälle finden. Bestehende Filtersysteme – wie zum Beispiel Kategorie-basierte Einordnungen – lassen sich somit ergänzen und Consim kann dem Benutzer den Zugang zu ähnlichen Fälle ebenen, die mit traditionelleren Ansätzen schwieriger zu finden wären. Beispiele für solche Anwendungen können juristische oder medizinische Fallsammlungen sein.
Funktionsweise
Das System extrahiert aus einer bestehenden Sammlung von Texte die Themengruppen, die in den Texten dieses Corpus behandelt werden.
Anschliessend werden die Texte eines zweiten Corpus analysiert, um zu ermitteln welche der erkannten Themen sie behandeln.
Je mehr übereinstimmende Themen zwei Texte behandeln, um so ähnlicher sind sie für das System.
Der Weg über zwei unterschiedliche Corpora eröffnet interessante Anwendungsfälle. So kann Consim beispielsweise mit Gesetzestexten trainiert werden, um anschließend ein Matching von Urteilen durchzuführen.
Technologie
Consim kombiniert Methoden der statistischen Textanalyse und des Deep Learning. Zu den verwendeten Machine Learning und NLP Methoden gehören insbesondere Topic Extraction und Algorithmen aus dem Text-Mining. Damit reiht sich Consim in eine Reihe von Anwendungen ein, die bei Folge 3 entwickelt wurden und Technologien aus der KI und dem Machine Learning in konkreten Szenarien nutzbar machen. Ein weiterer solcher Anwendungsfall ist unsere Vorhersage von Online Reichweiten mit Hilfe eines Neuronalen Netzes.
Wenn Sie Interesse an Consim oder ganz allgemein an unseren KI-basierten Anwendungslösungen haben, melden Sie sich gerne unter data@folge3.de