–
Category Archives: project
Digital puzzle fun
From simple to hellish. From A – Z.
Whether you prefer to elicit the carefully guarded word from the little tiger, let the letterbee bring letters and form words until your head starts spinning, or to think around the corner on a Sunday morning – everyone will find something here and get to pondering.
Datenanalyse-Software für transparente Durchlaufzeiten
In Zusammenarbeit mit dem Mittelstand-Digital Zentrum Ruhr-OWL konnten wir weiter an der Aufgabe arbeiten, unsere Analyse-Software für Unternehmen aus dem Bereich Logistik zu schärfen. Im Rahmen dieser Zusammenarbeit ist der folgende Artikel unter der Rubrik Erfolgsgeschichten auf der Site des Mittelstand-Digital Zentrums Ruhr-OWL erschienen:
Folge 3 GmbH erarbeitet Minimum Viable Product mit Mittelstand 4.0-Kompetenzzentren
Schnelle Produktionsprozesse, verlässliche Liefertermine: Wenn Kundenansprüche wachsen, gewinnt die Auftragsdurchlaufzeit an Bedeutung. Mit einer neuen Software zur Datenanalyse will die Folge 3 GmbH Unternehmen bei der Optimierung ihrer Prozessdurchlaufzeiten unterstützen – und gleichzeitig eine neue Zielgruppe erschließen. Der Hamburger Spezialist für Datenanalyse hat in der Medienbranche namhafte Kunden. Jetzt sollen Logistikunternehmen hinzukommen. Ein Ziel, das Folge 3 zusammen mit Digital in NRW und dem Mittelstand 4.0-Kompetenzzentrum Hamburg verfolgt.
Datenanalyse als Basis für Optimierungen
Welche Schritte muss ein Kundenauftrag durchlaufen? Welche Zeit nimmt das in Anspruch? Und warum dauert es zum Teil (zu) lang? Antworten auf diese Fragen geben Prozessdaten. „Diese liegen auch in vielen kleinen und mittleren Betrieben vor. Nur werden sie nicht konsequent analysiert“, erklärt Prof. Dr. Axel Wagenitz, Leiter des Business Innovation Labs an der Hochschule für Angewandte Wissenschaften Hamburg und Konsortial- partner im Kompetenzzentrum Hamburg. Das soll in Zukunft die Datenanalyse-Software WILMA übernehmen. Das Analysetool kann Rohdaten untersuchen, Prozesse identifizieren und in eine Prozessstruktur überführen. „Zudem werden relevante logistische Indikatoren und Kennzahlen implementiert und die Software ermittelt, welche Faktoren ausschlaggebend für erfolgreiche oder weniger erfolgreiche Prozessdurchläufe sind“, so Folge 3-Geschäftsführer Christoph Fröhlich. Werden die Prozesse anhand dieser Daten analysiert, entsteht die Grundlage für gezielte Optimierungen.
Neues Produkt für Logistikunternehmen
Unterschiedliche Produktionszeiten von Aufträgen. Das Verhältnis von Auftrags- und Mitarbeiterzahlen. Unnötige Liegezeiten zwischen Fertigung und Versand: Daten können aufdecken, was im Unternehmensalltag verbessert werden kann – und wie. „Dennoch haben wir den Eindruck, dass viele Logistikunternehmen bei der Datennutzung noch am Anfang stehen“, so Christoph Fröhlich. „Daten werden zwar gesammelt, aber mit der Auswertung und Aufbereitung zur Nutzung hapert es. Hier herrscht hoher Bedarf und gleichzeitig großes Interesse, etwas an der Situation zu ändern.“ Aus diesem Grund hat Folge 3 das Datenanalyse-Tool in Zusammenarbeit mit dem Kompetenzzentrum Hamburg auf die Logistikbranche ausgerichtet. Gemeinsam mit Digital in NRW wird das Konzept zur Optimierung der Prozessdurchläufe weitergeführt, ein marktreifes Produkt entwickelt und mit Logistikunternehmen getestet.
Zentrale Features im Fokus
„Im ersten Schritt haben wir einen Geschäftsmodell-Workshop gemacht und grundlegende Fragen geklärt“, blickt Alexander Krooß, Wissenschaftlicher Mitarbeiter am Fraunhofer IML und Projektleiter bei Digital in NRW, auf den Beginn der Zusammenarbeit zurück. „Was kann das Produkt? Welche Zielgruppe soll erreicht werden?“. Schnell wurde deutlich: WILMA ist ein Tool mit vielen Features zur Datenanalyse, Datenauswertung und -aufbereitung, aber ohne direkten Kundenbezug. „Wir haben die Software über zwölf Monate hinweg entwickelt. Da kam ein Feature nach dem anderen hinzu“, erklärt Christoph Fröhlich. „Jetzt möchten wir das Ganze entschlacken, auf zentrale Funktionen konzentrieren und diese zur Anwendung bringen.“
Mehr Planungssicherheit
Im Zentrum der Pilotierung, die seit Anfang März läuft, steht daher das Clustern von Prozessdurchläufen mit Hilfe von statistischen Verfahren und künstlicher Intelligenz. „Das Tool identifiziert bestimmte Merkmalskombinationen, z.B. eines Auftrags, die zu guten oder auch zu langen Durchlaufzeiten führen“, so Alexander Krooß. „Sind diese Eigenschaften und die daraus resultierenden Ergebnisse bekannt, können konkrete Änderungen beispielsweise an den Prozessen oder der Produktions- und Auftragsplanung vorgenommen werden.“
Feinschliff für die User Experience
Auch an der User Experience und am User Interface wird bis zum Projektabschluss Ende Juni noch gearbeitet. Dann soll das Minimum Viable Product erstellt sein. „Das ist ein straffer Zeitplan“, sagt Alexander Krooß. „Aber wir arbeiten bereits mit ersten Unternehmen als Pilotpartner zusammen und haben schon einiges geschafft.“ Das sieht Folge 3-Geschäftsführer Christoph Fröhlich ähnlich: „Wir sind schon weit. Zurzeit machen wir die Software intuitiv nutzbar. In enger Zusammenarbeit mit Digital in NRW bekommt sie jetzt den letzten Feinschliff“.
Digitales Kreuzworträtsel
… english translation coming soon …
Wie kann die Auslastung an Packtischen optimiert werden?
… english translation coming soon …
Data Analytics für das digitale Produkt
Folge Product Analytics ist eine Analyse-Lösung von Folge 3, die dem Produktentwickler eine datenbasierte Sicht auf das digitale Produkt zur Verfügung stellt.
Product Analytics
Folge Product Analytics funktioniert ähnlich wie Web Analytics. Während in Web Analytics aber nur das Nutzerverhalten auf der Seite oder in der App analysiert wird, berücksichtigt Product Analytics alle Daten, die für das digitale Produkt relevant sind. Diese Daten können aus den unterschiedlichsten Quellen stammen: interne Produktdatenbanken, Abverkaufszahlen, das Nutzertracking, Social-Media, Newsletter, die Userdatenbank, Daten von Partnern etc …
Folge Product Analytics bietet eine umfassende Sicht auf das digitale Produkt und ergänzt die traditionellen unternehmerischen Perspektiven um eine analytische Sicht. Unsere Lösung trägt zu einem vertieften Produktverständnis bei und vervollständigt die Entscheidungsgrundlagen für die strategische Fortentwicklung. Darüberhinaus unterstützt es bei der Aufgabe, die Datennutzung im Unternehmen zu verankern und zu intensivieren.
Der Ansatz
Folge Product Analytics basiert auf einem Baukasten-System, mit dem sich individuelle Lösungen passgenau für Ihre Anforderungen zusammenstellen lassen.
Big Data: Je mehr Datenquellen die Lösung nutzen kann, umso hilfreicher ist sie. Deshalb ist die Plattform so ausgelegt, dass beliebige Daten in jeder Größenordnung importiert und analysiert werden können.
Jedes Produkt ist anders: Weil kein Produkt dem anderen gleicht, bietet Folge Product Analytics keine starren vordefinierten Ansichten und Analysen, sondern alle Auswertungen und Strukturen lassen sich individuell erstellen. Und während sich das reale Produkt über die Jahre entwickelt, kann Folge Product Analytics kontinuierlich angepasst werden und hält mit der Entwicklung Schritt.
Das Rad wird nicht jeden Tag neu erfunden: Zwar gleicht kein Produkt dem anderen. Aber ebenso wird das Rad nicht an jedem Tag neu erfunden. Die grundsätzlichen Ansätze analytischer Datenverarbeitung sind einigermaßen universell und lassen sich auf die meisten Produkte anwenden. Deshalb bringt unsere Lösung viele fertige Module und Bausteine von Haus aus mit. So lassen sich mit wenig Aufwand in kurzer Zeit maßgeschneiderte, stabile Anwendungen aufbauen, die genau auf ihr Produkt zugeschnitten sind.
Daten für alle? … eigentlich nicht. Zugriff sollen nur die bekommen, die berechtigt sind und für diese soll es einfach sein. Folge Product Analytics bietet klare Mechanismen zur Steuerung von Zugriffsrechten und stellt sicher, dass Ihre Daten nur von denen gesehen werden können, die auch das Recht dazu haben.
Wissen aufbauen oder Maßnahmen veranlassen? Folge Product Analytics macht da keinen Unterschied. Alle Ergebnisse stehen auch maschinenlesbar über HTTPS für autorisierte Nutzer zur Verfügung und können so an nachfolgende Systeme übergeben werden. Dadurch lassen sich Analyse-Ergebnisse direkt in der Produktion und / oder der Ausspielung nutzen.
Das Baukastensystem
Folge Product Analytics bringt eine Vielzahl von Modulen mit, die den Aufbau individueller Anwendungen schnell und einfach machen. Beispielsweise lassen sich die folgenden Anforderungen einfach erledigen:
Performance-Indikatoren definieren: Wie Performance gemessen wird, ist in jedem Projekt unterschiedlich. Folge Product Analytics erlaubt die Definition individueller Performance-Indikatoren, sowohl von Einzel- als auch von Composite-Indikatoren.
Engagement-Scores berechnen: Engagement ist eine zunehmend verbreitete Methode um die Bedeutung von Angeboten zu messen. Wenn Sie Folge Product Analytics nutzen, können sie beliebig komplexe individuelle Engagement-Scores definieren.
Prognosen erstellen: Für alle Zielgrößen und Zeiträume die von den Daten abgedeckt werden, lassen sich Prognosen erstellen. Eine Vielzahl von Verfahren – vom einfachen statistischen Durchschnitt bis hin zum komplexen Neuronalen Netz – stehen zur Erstellung der Vorhersagen bereit.
Segment-Analyse durchführen: Oft will man die Ergebnisse innerhalb eines oder mehrerer Segmente vergleichen. In Folge Product Analytics lassen sich Segmente definieren und mit Filtern, Zeiträumen und Visualisierungen zu ausdrucksstarken Analysen kombinieren.
Für viele weitere Aufgaben stehen ebenfalls Module bereit.
Das Setup
Während der Inbetriebnahme von Folge Product Analytics erarbeiten wir gemeinsam mit Ihnen das ideale Setup für Ihren Anwendungsfall und unterstützen Sie bei Bedarf sowohl konzeptionell als auch in der Implementierung.
Wir bewerten gemeinsam mit Ihnen die relevanten Daten, führen Importe durch, diskutieren mögliche Performance-Indikatoren, erstellen Strukturen, Ansichten und Analysen und binden – falls es gewünscht ist – weitere Systeme ein. Zusätzlich schulen wir Ihre Mitarbeiter, so dass das Tool vom ersten Tag an produktiv genutzt werden kann.
Über die Inbetriebnahme hinaus bieten wir weitere Services und Schulungen, die es Ihnen erlauben, das Bestmögliche aus Folge Product Analytics herauszuholen:
- Schulung Ihrer Entwickler, so dass Sie individuelle Anpassungen auch inhouse vornehmen können
- Durchführung von Workshops und Schulungen, in denen die Teilnehmer lernen, wie Self-Service-BI die avancierte Nutzung der Rohdaten ermöglicht
- Unterstützung bei der Analyse: Wir bringen Ideen für Analyse auf, diskutieren mit Ihnen Analyse-Ansätze, wählen Methoden aus und zeigen Ihnen wie Sie sie in Folge Product Analytics einbinden können
Für genauere Auskünfte rund um Folge Product Analytics melden Sie sich gerne unter data@folge3.de
academics
… comming soon …
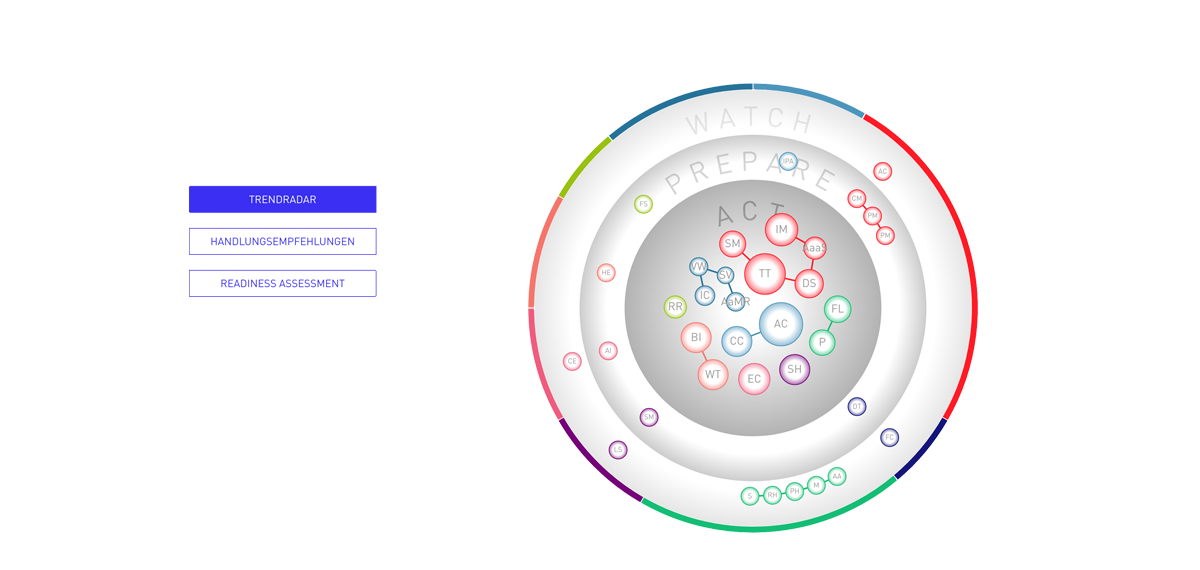
Trendradar
TRENDONE is a renowned Hamburg consulting firm for strategic future issues & trends.
In times when disruptive ideas, innovative developments and radical technical progress challenge many industries, enterprises structure themselves increasingly new. Innovation processes are being embedded into organizations and are the foundation for continuous adaptation of future development. TRENDONE provides substantial information about current trends for many different business environments. In addition, the Hamburg-based company has created a platform with the necessary tools for researching, evaluating and recording future developments and provides insights how a company is prepared for relevant trends.
One of these tools is the Trendmanager with the integrated Trendradar. The Trendmanager assists companies to detect relevant developments from all mega, macro and micro trends identified by TRENDONE. It allows them to store all findings in a company-specific trend pool and evaluates their future impact on the company. For these tasks, the Trendradar offers various views that categorize trends and correlates them. The view “Recommendations for Action” is subdivided into the three fields “Act”, “Prepare” and “Watch” and provides an overview of how relevant trends should be taken into account for innovation processes and corporate decisions. “Readiness Gap“ delivers insights into weaknesses and excellences of a company and where the focus should be set to ensure a successful future development.
In close cooperation with TRENDONE Folge 3 developed the views of the Trendradar over a period of several months by subsequently creating the visual concept and finally ensuring the implementation of the dynamic and animated views.
KI-Prognose-Systeme für die Logistik
Die Anwendungsgebiete für Künstliche Intelligenz in der Logistik sind vielfältiger Natur und über die ganze Supply Chain verteilt. Insbesondere Prognose-Systeme zur Auslastungsplanung stellen einen vielversprechenden Ansatz dar.
Wer hätte das vor 20 Jahren gedacht? Die Logistik-Branche wurde im Zuge der Digitalisierung nicht bedeutungslos, sondern das Gegenteil trat ein. Der Online-Handel boomt, immer mehr Produkte wollen verschickt werden und die Branche jagt von einem Rekord zum nächsten.
Mit den Mengen steigen auch die Anforderungen. Die Supply Chains werden stetig komplexer und die Abläufe müssen effizienter und effektiver werden. Gleichzeitig entstehen immer umfassendere Datenmengen, die genutzt werden können, um Prozesse zu optimieren, Muster zu erkennen oder Vorhersagen zu treffen.
Neuronale Netze sind ein Game Changer
Wo kein Mensch mehr die Menge der Daten überblicken und Rückschlüsse daraus ziehen kann, helfen Methoden des Machine Learning und der Künstlichen Intelligenz (KI). Insbesondere mit neuronalen Netze lassen sich Prognose- und Klassifizierungs-Probleme effizient angehen.
Dabei beschreiten Neuronale Netze einen ganz eigenen, neuartigen Lösungs-Ansatz. Sie sind mit den übrigen Verfahren des Machine Learning nicht vergleichbar und sie eröffnen Wege, wo bisher kein Weiterkommen war.
Entsprechend euphorisch sind die Hoffnungen, die mit ihrem Einsatz verbunden sind. Beispielhalber soll hier die McKinsey-Studie zum Potential neuronaler Netze erwähnt werden.
KI in der Logistik
Die Anwendungsgebiete für KI in der Logistik sind vielfältiger Natur und über die ganze Supply Chain verteilt. Eine Studie der IDG vom September 2018 führt insbesondere die folgenden drei Bereiche auf, in denen die Unternehmen über den Einsatz von KI nachdenken
- Optimierung der internen Prozesse
- Verbesserung der Kundenbeziehung
- Verbesserung der Fertigungsprozesse
Zwar sind viele Unternehmen noch in der Analysephase und haben noch keine Projekte realisiert, aber insbesondere bei den großen Anbietern lassen sich schon konkrete Beispiele finden, wie KI und Machine Learning in der Logistik erfolgreich eingesetzt wird.
Im E-Commerce lassen sich Absatzprognosen erstellen, um nachgefragte Waren in ausreichender Stückzahl vorzuhalten, wie es z.B. Otto macht. Zalando optimiert im Auslieferungs-Lager die Pickwege, um Aufträge schneller versandfertig zu bekommen. Und wir bei Folge 3 optimieren die Auslastung von Packbereichen, in dem wir prognostizieren, wie lange es braucht, um eine Bestellung versandfertig zu machen.
Entscheidend ist eine gute Datenbasis
Allerdings eignet sich nicht jede Idee für eine Umsetzung mit Machine Learning und KI. Nicht weil die Idee schlecht ist. Sondern weil die Daten, die zur Realisierung notwendig sind, nicht vorliegen.
Jedes Projekt, das Technologien aus der Data sciene einsetzen möchte – seien es Neuronale Netze, Recommender, Prognose-Systeme oder ähnliches – benötigt eine umfassende, qualitative Datenbasis. Die Daten sollten möglichst wenig Ausreißer enthalten, genügend Datensätze aufweisen und sie müssen ausreichend viele Merkmale aufweisen, um die gestellte Aufgabe aus den Daten heraus lösen zu können.
Insbesondere bei Prognose-Aufgaben ist es sehr wichtig, möglichst alle Merkmale, die für die Vorhersage der Zielgröße relevant sind, auch in den Daten zur Verfügung zu haben.
Oft stellt sich im Projekt heraus, dass nicht all diese Daten zur Verfügung stehen und eventuell auch gar nicht quantifizierbar sind oder nur mit erheblichem Aufwand beschafft werden können. Aus diesen Gründe ist es von Vorteil, DataScience-Projekte immer mit einer ausführlichen Analyse der vorliegenden Daten zu beginnen. Andernfalls besteht die Gefahr, dass Ressourcen in ein Projekt gesteckt werden, das sich später als undurchführbar erweist und abgebrochen werden muss.
Wenn Sie Nachfragen zu diesen Themen haben oder Sie sich für die Einsatzmöglichkeiten von KI in der Logistik interessieren, melden Sie sich gerne unverbindlich unter data@folge3.de
Consim: Ähnliche Texte finden
Consim ist ein Matching-System für Text. Mit Consim lassen sich Texte identifizieren, die ähnliche Themen behandeln. Consim erkennt die Ähnlichkeit von Texten mit Hilfe von Machine Learning und Natural Language Processing rein auf inhaltlicher Basis. Es werden keine Besucher-Daten oder weitere Meta-Informationen benötigt.
Beispielsweise kann Consim in den Angeboten eines Nachrichten-Verbundes Texte zu ähnlichen Themen finden. Sogar dann, wenn Sie auf verschiedenen Portalen gehostet werden. Oder Consim kann mit den Gesetzestexten eines Rechtsgebietes trainiert werden und findet dann Gerichtsurteile, in denen die jeweiligen Themen behandelt werden.
Ähnlichkeit basiert auf dem Inhalt
Um Consim einzusetzen reicht es, Zugriff auf die Inhalte zu haben. Metadaten wie Kategorisierung, Quelle oder ähnliches können als zusätzliche Hilfestellung mit in den Matching-Prozess einfliessen, sind aber nicht nötig.
Das System basiert auch nicht auf der Auswertung von User-Daten. Es ermittelt also nicht – anders als der klassische Amazon-Recommender – dass ein User, der Produkt A mochte, auch Produkt B angeschaut hat. Vielmehr identifiziert Consim Wortgruppen, die eine thematische Einordnung des Textcontents erlauben.
Dadurch, dass Consim nur den Inhalt in Betracht zieht, funktioniert das System auch direkt für neu eingestellte Texte – es gibt kein Cold-Start-Problem – und auch in Bereichen, in denen nur wenige oder gar keine User-Interaktionen statt finden.
Use-Cases
Consim kann beispielsweise für die folgenden Anwendungsfälle eingesetzt werden:
- Online-Nachrichtenportale: Mehr und mehr Nachrichtenportale setzten auf einen Mix aus freien News und Premium-Inhalten, die hinter einer Bezahl-Schranke liegen. Mit Hilfe von Consim lassen sich thematische Verbindungen finden, die von den freien, hoch frequentierten Online-Angeboten auf die weniger oft aufgerufenen Bezahl-Inhalte führen. Klassische Recommender-Lösungen scheitern hier, weil die Bezahl-Inhalte zu wenig Reichweite haben, um von den statistischen Verfahren berücksichtigt zu werden.
- In Matching – Szenarien, in denen individuelle, profil-basierte Vorschläge erstellt werden, läßt Consim sich ebenfalls einsetzen. Voraussetzung ist, dass die Informationen, die zur Identifikation von Interessen und zur Herausarbeitung eines Profils verwendet werden, in Textform vorliegen. Dazu können sowohl vom User generierte als auch von ihm konsumierte Inhalte verwendet werden. Ein Anwendungsfall ist das Matching von Studieninteressen mit Studiengangs-Beschreibungen. Ein anderer ist die Suche in Stellenangeboten, wo die bereits besuchten und als interessant bewerteten Angebote das Profil ergeben, zu dem sich ähnliche Angebote finden lassen.
- In Expertensystemen oder Fallsammlungen für Spezialisten lassen sich mit Consim ähnliche Fälle finden. Bestehende Filtersysteme – wie zum Beispiel Kategorie-basierte Einordnungen – lassen sich somit ergänzen und Consim kann dem Benutzer den Zugang zu ähnlichen Fälle ebenen, die mit traditionelleren Ansätzen schwieriger zu finden wären. Beispiele für solche Anwendungen können juristische oder medizinische Fallsammlungen sein.
Funktionsweise
Das System extrahiert aus einer bestehenden Sammlung von Texte die Themengruppen, die in den Texten dieses Corpus behandelt werden.
Anschliessend werden die Texte eines zweiten Corpus analysiert, um zu ermitteln welche der erkannten Themen sie behandeln.
Je mehr übereinstimmende Themen zwei Texte behandeln, um so ähnlicher sind sie für das System.
Der Weg über zwei unterschiedliche Corpora eröffnet interessante Anwendungsfälle. So kann Consim beispielsweise mit Gesetzestexten trainiert werden, um anschließend ein Matching von Urteilen durchzuführen.
Technologie
Consim kombiniert Methoden der statistischen Textanalyse und des Deep Learning. Zu den verwendeten Machine Learning und NLP Methoden gehören insbesondere Topic Extraction und Algorithmen aus dem Text-Mining. Damit reiht sich Consim in eine Reihe von Anwendungen ein, die bei Folge 3 entwickelt wurden und Technologien aus der KI und dem Machine Learning in konkreten Szenarien nutzbar machen. Ein weiterer solcher Anwendungsfall ist unsere Vorhersage von Online Reichweiten mit Hilfe eines Neuronalen Netzes.
Wenn Sie Interesse an Consim oder ganz allgemein an unseren KI-basierten Anwendungslösungen haben, melden Sie sich gerne unter data@folge3.de