Für ZEIT ONLINE hat Folge 3 das CHE-Hochschulranking wieder überarbeitet:
http://ranking.zeit.de/che2014/de/
Web-Ontology Hochschulranking
Für das Hochschulranking 2014 wurde ein neuer, thematisch orientierter Zugang eingeführt, der die bisherigen Einstiege über Fächer und Orte konsequent ergänzt. Dieser neue Zugang öffnet das Angebot des Hochschulrankings auch für die Interessierten, die noch keine exakte Vorstellung davon haben, was beziehungsweise wo sie studieren wollen.
Das Hochschulranking von ZEIT ONLINE und CHE
Das Hochschulranking von ZEIT ONLINE und CHE (Centrum für Hochschul-Entwicklung) veröffentlicht jährlich Rankings zu den Studienbedingungen von über 40 Fächern an Hochschulen im deutschsprachigen Raum.
Der Einstieg in das Ranking ist traditionell über Fächer oder über Hochschulorte möglich. Diese Form des Zugangs liegt nahe, denn viele angehende Studenten haben entweder eine Idee davon, was oder wo sie studieren wollen. Gleichzeitig ist die Umfrage-Datenbank nach Orten, Hochschulen und und Fächern organisiert und unterstützt diese Form des Zugangs gleichsam von Haus aus.
Dennoch erweisen sich diese Zugangsmöglichkeiten in manchen Fällen als unzureichend. Zum einen ist Studienanfängern häufig unklar, welches Fach ihre Interessen überhaupt abdeckt (beispielsweise Informatik oder Technische Informatik oder Elektrotechnik). Zum anderen macht die zunehmende Ausdifferenzierung der Studienangebote, insbesondere in den Ingenieurswissenschaften, die Reduktion auf 40 Fachgebiete problematisch.
In dieser Situation hat sich das Projektteam von ZEIT ONLINE entschieden, einen neuen, zusätzlichen Einstieg ins Hochschulranking zu entwickeln. Der neue Einstieg soll einen thematischen Zugang etablieren und auch den Studenten den Zugang zum Ranking ermöglichen, für die gilt: “Ich weiss nicht genau, was ich studieren will. Aber ich interessiere mich für irgendwas mit…”
Neuer Zugang als Ontologie
Der traditionelle Zugang zum Hochschulranking findet über Fächer oder Orte statt. Fächer und Orte sind expliziter Teil des relationalen Modells des Hochschulrankings. Um alle Studiengänge auszulesen, die ein bestimmtes Fach anbieten, genügt eine einfache Datenbankabfrage. Ähnliches gilt für den Zugang über Orte. Im Gegensatz dazu sind die Themen, die ein Studiengang abdeckt, nur implizit in den Daten vorhanden. Die Informationen sind vorhanden, aber sie sind nicht distinkt, nicht abfrage-bereit in der relationalen Struktur ausgewiesen.
Um den neuen Einstieg aufzubauen, mussten wir daher zwei Aufgaben lösen: Zum einen aus dem Datenbestand Begriffe ermitteln, die die Themen der Studiengänge abbilden. Die dabei entstehende Begriffswelt bildet das spätere Frontend.
Zum anderen mussten Abbildungsregeln erstellt werden. Diese Regeln werden benutzt, um ausgehend von einem gewählten Begriff eine passende Auswahl von Studienangeboten und Rankings zu ermitteln. Die Kombination aus Begriffen und Regeln ergibt die Ontologie.
Ontologie: In der Informatik bezeichnet “Ontologie” eine Kombination aus strukturiertem Begriffsraum und Regeln, wie die Begriffe miteinander oder mit einem Außen interagieren sollen.
Erstellung der Web-Ontologie
Kategorien als erster Einstieg
Schnell wurde deutlich, dass die thematische Vielfalt des Hochschulrankings zu groß ist, um alle interessanten Begriffe auf einer Ebene präsentieren zu können. Daher haben wir uns dafür entschieden, das Frontend als zweistufige Hierarchie zu gestalten. Auf der ersten Ebene wird eine grobe thematische Kategorisierung dargestellt. Diese führt auf die zweite Ebene, auf der eine TagCloud den Begriffsraum der jeweiligen Kategorie aufspannt.
Die Kategorien wurden von der ZEIT Studienführer-Redaktion übernommen, die in diesem Jahr eine grobe Einteilung der Studiengebiete in sechs Haupt-Kategorien erstellt hat.
Der ZEIT Studienführer veröffentlicht das Hochschulranking jährlich als Print-Magazin. Zusätzlich zu den Daten finden die angehenden Studenten dort Einschätzungen und Beschreibungen, die ihnen helfen, sich in der neuen Welt “Hochschule” zurecht zu finden.
Initiale Begriffswelt
Die erste Fassung der Begriffswelt sollte aus den im Hochschulranking enthaltenen Daten extrahiert werden. Als Ausgangspunkt hatten wir die folgenden Inhalte:
- Die Namen der etwa 4500 Studiengänge
- “Schlagwörter” zu den Studiengängen
Die Schlagwörter werden von den Fachbereichen vergeben. Sie dienen als Keywords für die lokale Suche des Hochschulrankings. Dieser “SEO”-Ursprung machte die Schlagwörter für unsere Zwecke besonders geeignet, besser als die Namen der Studiengänge.
Denn die Namen der Studiengänge sind „Diener vieler Herren“ und müssen unterschiedlichen Anforderungen genügen. Unter all diesen Anforderungen ist es nur eine von vielen, den Inhalt des Kurses für Studienanfänger in allgemein verständlicher Form zu beschreiben. Im Gegensatz dazu, sind die Schlagwörter auf genau diesen Zweck hin getextet und vergeben.
Aus diesen beiden Quellen – Schlagwörtern und Namen – haben wir mit Hilfe von Solr eine erste Fassung des thematischen Raums erstellt. Die Schlagwörter und die Namen der Studiengänge wurden in Wortbestandteile (Terme) aufgespalten, die Terme wurden auf ihre Grundformen zurückgeführt und die Liste der Terme wurde reduziert, so dass nur Terme, die in mindestens 5 unterschiedlichen Studiengängen auftauchen, im weiteren Verlauf berücksichtigt wurden.
Solr ist ein freier Suchserver aus dem Apache Lucene Projekt (lucene.apache.org). Obwohl die klassische Aufgabe von Lucene die Volltextsuche ist, kann es auch sehr effektiv für Information Retrieval-Zwecke eingesetzt werden, insbesondere für Text-Mining.
Programmatisch erstellte Basis
Als Ergebnis dieses Prozesses entstand eine Excel-Liste mit etwa 3000 Zeilen, die die grundlegende Begriffswelt des Hochschulrankings abbildete.
Erste manuelle Nachbearbeitung
Im nächsten Schritt wurde diese Datei manuell nachbearbeitet. Einzelne Terme aus den Schlagwörter und Namen wurden zu Konzepten zusammengefasst. Zum Beispiel könnten “fahrzeugtechnik”, “fahrzeugbau”, “fahrwerk”, “fahrzeugelektronik” zum Konzept „Fahrzeugbau“ gehören.
Anschliessend wurde jedes Konzept einer Kategorie zugeordnet.
Das war ein rein manueller Prozess, der nicht mehr als einige Stunden in Anspruch nahm. Es gab immer mal Begriffe, die sich nicht eindeutig zuordnen liessen. Wenn sie in mehr als eine Kategorie passten, wurden sie beiden Kategorien zugeordnet. Manche Begriffe passten auch in keine Kategorie. Sie wurden dann entweder in eine Kategorie “gepresst” oder entfielen ganz.
Kontrolle im Frontend und weitere Nachbearbeitung
Anschliessend wurde die Ontologie programmatisch umgesetzt und konnte von den ZEIT-ONLINE-Mitarbeitern in einer Entwicklungsumgebung benutzt werden. Damit begann die Feinabstimmung, der aufwendigste Teil des manuellen Prozess, denn erst in der Darstellung im Frontend fielen die Schwächen der bisher erstellten Ontologie deutlich auf.
Manche Kategorien waren zu breit. Sie enthielten zu viele Begriffe, um sinnvoll genutzt werden zu können.
Für manche Begriffe ändert sich zudem die Bedeutung im Kontext der Kategorie. Ein Elektrotechniker interessiert sich bei “Medien” eher für deren technische Ausgestaltung während in den Geisteswissenschaften die kulturellen Ausformungen im Vordergrund stehen. Für diese Begriffe mussten in den Abbildungsregeln zusätzliche Constraints eingebaut werden, je nachdem aus welchem thematischen Kontext die Suche stammte.
Diese Verfeinerung – oder auch “Kuratierung” – der Ontologie machte am meisten manuelle Arbeit. Sie muss von Personen mit gutem Allgemeinwissen und einem Gespür für die Verständnishorizonte der Zielgruppen durchgeführt werden. Entscheidungen müssen getroffen werden und die Ontologie verliert einen absoluten Anspruch. Sie ist keine vollständige, exakte Abbildung der vorliegenden Daten mehr, sondern sie wird zu einem Hilfsmittel, das in vielen Fällen den Zugang erleichtern kann, in manchen Fällen aber nicht weiter hilft. Dieser Schritt – von der rein mechanischen Abbildung zum kuratierten Themenraum – erzeugte den entscheidenden Mehrwert, was die Benutzbarkeit angeht.
Fazit
Der Einsatz von Text-Mining-Technologie, gepaart mit manueller Nachbearbeitung, ermöglicht die Erstellung von Web-Ontologien. Dadurch lassen sich implizit in den Daten enthaltene Information externalisieren und als Navigations-Angebot auf der Site nutzen. Der Prozess kann initial automatisiert durchgeführt werden. Durch manuelle semantische Nachbearbeitung kann so die Qualität der Ontologie deutlich gesteigert werden.
– – – – – – – – – – –
07.07.2014
Christoph Fröhlich
Digitale Archive
Die Museen der Stadt Dresden wollen ihre Archive für alle Interessierten digital zur Verfügung stellen. Wir haben den Pitch für das Web-Tool gewonnen.
Launch U-Multirank
U-Multirank ist ein multidimensionales, nutzergeführtes Tool, um die Studienangebote an Hochschulen zu bewerten. Insgesamt haben 500 Institutionen aus Europa und der ganzen Welt daran teilgenommen.
Folge 3 ist Partner eines internationalen Konsortiums, das U-Multirank für die Europäische Kommission entwickelt. Wir sind verantwortlich für die Brand Strategie, die Logo- und Web-Toolentwicklung.

Who-post

U-Multirank Sunburst
U-Multirank is a new multidimensional, user-driven approach to international ranking of higher education institutions.
As a benefit U-Multirank provides an individualized seal for each institution representing the results of the indicators in each dimension as a downloadable element. All measures are grouped around the central symbol of U-Multirank, the „u“ on a circle-shaped button. All graphic elements refer to the identity of the web-tool and persue the corporate design of U-Multirank.
The seals are positioned on the profile page of each institution and can be downloaded by the universities for multiple use.

Monitor Lehrerbildung
Transparency in diversity in teacher education: The “Monitor Lehrerbildung” (teacher education monitor) platform provides current information and data about the various arrangements for teacher training within the individual German federal states and at the respective national universities for fact-based discussions and decisions.
The aim of the project is to create the comparability needed for a discussion. It focuses on target groups concerned with teacher education, i.e. politicians, journalists and players from teacher training, universities and ministries.
The project duration is set initially for the next five years. In addition to data updates, several extensions of the portal are set to take place during this period. We have already developed the diagram level as a first step. Thus the data can be retrieved in the conventional table view as text or as a graphic representation.
Project partners are the Bertelsmann Foundation, the CHE Centre for Higher Education Development, the Deutsche Telekom Foundation and the Stifterverband für die Deutsche Wissenschaft (Association for the Promotion of German Science and Humanities).
Cooperation
We have been cooperating with the Swiss companies One Inside and Unic AG. In international project teams, we work on web presences for major customers of both companies.
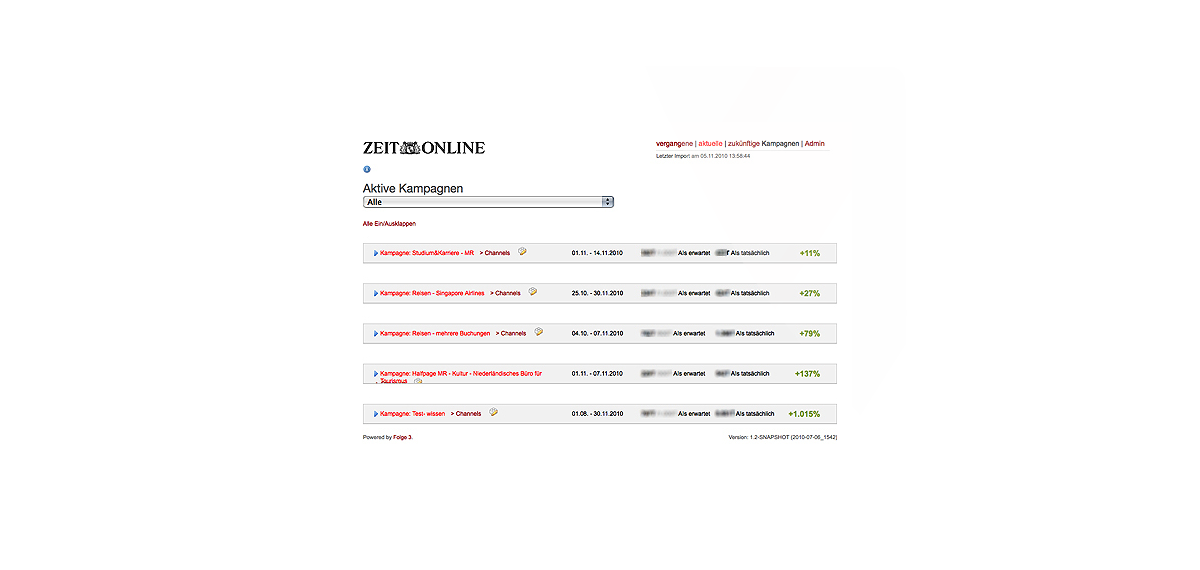
ClickCounter
ZEIT ONLINE Counters is the generic term for a series of tracking and analysis tools that capture the relevant online figures in near real-time. For ZEIT ONLINE, they represent a complement to web analytics tools such as Omniture or WebTrekk for its day-to-day work.
The counters are optimized for at-a-glance overviews. The key figures are presented graphically from different viewpoints. The results can then serve as a decision-making basis for further planning of tenders. All counters come with their own web and HTML5 mobile interface and can also be integrated into the CMS via a REST API.
ClickCounter: The ClickCounter counts the number of hits on the editorial pages of ZEIT ONLINE. The source is a web beacon. The hits for the article are evaluated every five minutes. The figures are graphically represented in five-minute intervals for the last hour and in one-hour intervals for the past 24 hours. Access is via a web interface, and programmatic access is possible via a REST API. ZEIT ONLINE also allows for integration into the CMS.
AdCounter: AdCounter counts the number of ad impressions for individual campaigns. The source is a web beacon. Campaigns can be defined in terms of time and be assigned to different channels. Values obtained are compared against expectations. The data are read every five minutes and are graphically represented. Furthermore, they are available down to the channel level. Past campaigns are archived.
TextCounter: The TextCounter gives information about the number of published articles per period/desk/author. The source is a Lucene SOLR index operated by ZEIT ONLINE. The search results are enriched with the corresponding values from the ClickCounter on an article basis.
Dashboard: The Dashboard collects the key figures from the individual counters and displays them graphically and textually. In addition, the current IVW (German Information Community for the Assessment of the Circulation of Media) data are integrated. To that end, the dashboard replaces the IVW Collectorbox at ZEIT ONLINE, which was taken down in 2011.
Zip codes in Germany
We visualized the zip code areas in Germany. Here you can download the data: